The Essential Guide to Scraping At Scale with Diffbot
Planning to scrape over a million pages? Here's how to do it without pulling your hair out.
Contents
- Web Data Extraction Benefits
- Web Data Extraction Use Cases
- Web Data Extraction Definitions
- The Four Routes To Extract Web Data
- Data Extraction Best Practices
- How To Extract Data From One Page (Non-Technical)
- How To Extract Data From One Page (Technical)
- How To Extract Data From An Entire Site (Non-Technical)
- How To Extract Data From An Entire Site (Technical)
- How To Extract Data From Across The Web (Non-Technical)
- How To Extract Data From Across The Web (Technical)
- Web Scraping Legality
Good artists borrow, great artists steal… Ethical artists, on the other hand, just make sure they follow robots.txt files.🧐 In short, great value often relies on the data from others. In this case, public web data.
While data lifecycles perhaps aren’t quite “art for art’s sake,” the single largest portion of gaining value from data is often in finding, extracting, and cleaning data for consumption. And this often means procuring unstructured data from the public web, and structuring it.
In fact, an estimated 90% of organizational data today is unstructured. And a lion’s share of new information in this form is public web data.
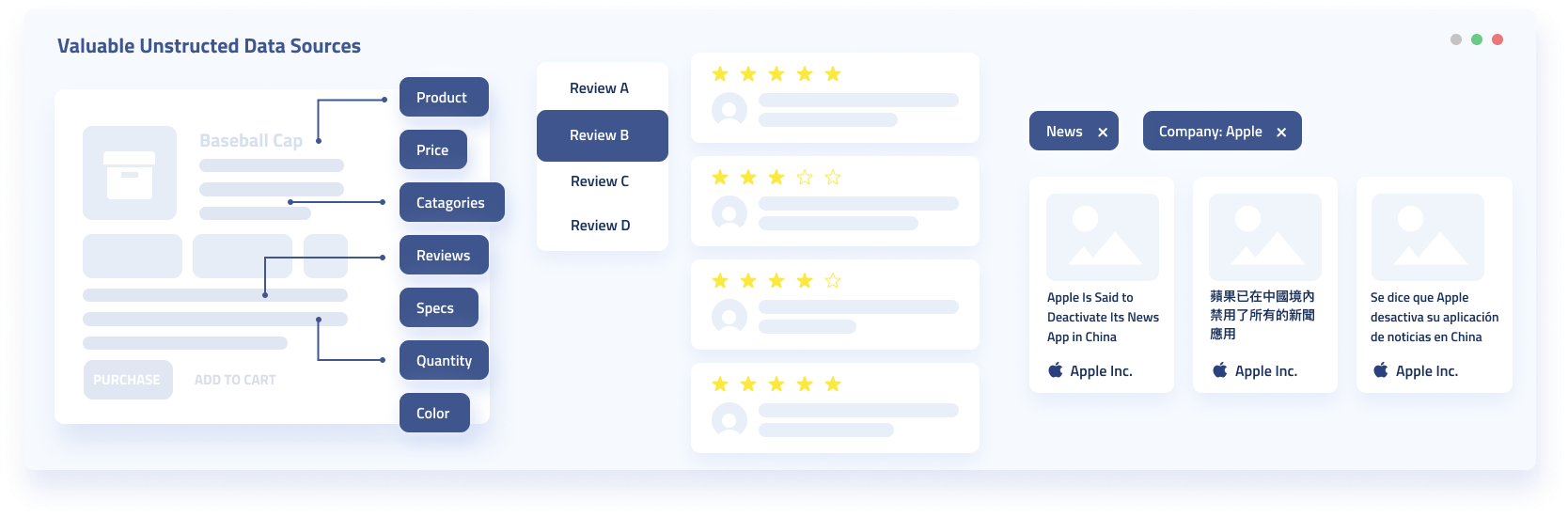
Product listings, pricing data, news mentions, sentiment analysis, cataloging, marketing intel, competitive analysis, and discussion data are all often sourced from the public web. And companies and individuals who can quickly and effectively source data of these types drastically speed up and increase the effectiveness of their data-driven products and services.
Data extraction (also known as web harvesting, data scraping, web scraping, and so forth) is the primary method through which unstructured web data is aggregated, cleaned, transformed, and made ready for consumption and analysis.
Many sites have data worth extracting. And relatively few sites provide functionality to save their format en masse in a structured usable format. This makes data extraction to some degree unavoidable.
The choices you do have relate to the best type of web extraction for your unique goals. Alternatively, one should consider whether one’s data needs are better catered to by vertical-specific data providers. There are arguments for both approaches, as well as many intermediate options including:
- DIY Extraction Tools
- In-House Web Data Extraction
- Vertical-Specific Data Providers
- And Knowledge-As-A-Service Providers
In this guide we’ll work through some of the most common extraction-related tasks and situations. For each we’ll provide a potential blueprint you can follow. Or at the very least the general questions and concepts one should consider when discerning the best route forward.
Web Data Extraction Benefits
The primary method for procuring public data from the web is through data extraction (also known as web harvesting, web scraping, data scraping, and so forth). Many sites have data worth extracting. But don’t provide the functionality to save their data in any structured, usable format.
The right data extraction method can preempt many data-centered issues such as:
- Data that’s out-of-date
- Data that’s inaccurate
- Data with no context
- Data without sources or lineage
- Data that’s unusable due to structure
The right data extraction method for you should also address practical concerns such as:
- Your level of technical know-how
- Your budget
- The schedule on which you need your data updated
- The quantity of data you need
- Whether you need homogeneous or heterogeneous structured data
- Whether you need data from a single site, a range of sites, or from across the whole web
This may seem like a great deal to consider. But in your effort to automate data accumulation, cleaning, and minimize data upkeep costs, no effort should be spared in advance. A vast majority of many data teams’ time is spent on aggregating and cleaning data. Understanding your data extraction options in advance can help to minimize these costs and provide more actionable data to boot.
In this guide we’ll seek to provide you with foundational terminology and concepts to make the right data extraction choice for your team. We’ll also look at many of the most common data extraction types and constraints and what you should do about them.
Web Data Extraction Use Cases
If you’ve made it this far, you likely already have some notion of why extracted web data could be valuable to you. But to provide an overview of many of the data-driven task types that can find value in data extraction we’ll list some of the most common below.
Here at Diffbot we’ve seen hundreds of valuable and unique applications of data extraction. The five major categories we see each apply to many verticals and roles in slightly different ways. These include:
- Market Intelligence
- Ecommerce
- Machine Learning
- News Monitoring
- And Custom Scraping
The output of a given use case also differs depending on the function of the individual or team seeking to utilize extracted web data. For example:
- Some users utilize the “up-to-date” nature of the web or a given site to feed data to a dashboard.
- Some users utilize semi-structured web data as useful machine learning training data that mimics conditions “in the wild” (of the internet).
- Some users utilize extracted web data as “alternative” data or to augment data silos manually curated by subject matter experts.
- Some users are primarily seeking to shore up their own data with data lineage or provenance.
- Some users are selling transformed web data. Web data (in some form) is their product or service.
Needless to say, we are now approaching data extraction from a birds-eye view. We’ve found this to be a useful exercise, however, as many teams seeking data extraction tools and expertise begin their search with one need in mind and often end with a different conception of what web data can provide for their case.
In summary, extracted web data can be useful anywhere data in-and-of-itself can be useful. Particular strong characteristics of web data that is extracted correctly include:
- Timeliness of data
- “Live” nature of some data
- Sourcing from experts beyond your org
- Scale of the data
- “In the wild” nature of web data
This doesn’t mean that you shouldn’t use data from other sources. But rather that in many cases the best source of data for your needs will include at least some web data.
Web Data Extraction Definitions
To make the most use of this guide on web data extraction methods, there are a few terms you should know in advance. For a series of related definitions, be sure to check out our Knowledge Graph Glossary.
Seed URLs are URLs from which an initial crawl of a domain takes place. Most websites can be thought of as a family tree-like structures wherein a home page links to pages for the major categories or actions on a site. In turn these category or action pages contain sub-pages. By establishing a seed URL you can specify the most general page you want to be crawled.
Web Crawlers are scripts that automatically catalog locations on the web. Often associated with bots created by search engines to “crawl” sites for inclusion in search results, crawlers are also essential for data extraction (that’s what Google and Bing are doing anyways, extracting markers they find relevant for providing search results).
Crawling is what web crawlers do. This process involves automatically accessing websites and obtaining data on visited pages via some software. Because the web is comprised of all sorts of things (often house in an unstructured or disorganized manner) you can think of crawling as the action of taking a huge stack of books and creating a “card catalog” of sorts.
Crawling Rules are the patterns that govern what pages web crawlers visit. Few entities want to crawl the entire web. And due to the time and resource-intensive nature of this task even those that do often provide rules for establishing how “important” it is to crawl a given page. High profile sites are crawled daily or by the hour. Small blogs that haven’t been updated in years typically don’t need to be re-crawled on a regular basis. For the many entities performing web extraction and not crawling the entire web, crawling rules help to point the crawler to the exact pages you want information from.
Robots.txt is a file included by website managers that provides details on which bots they give consent (or don’t give consent) to crawl. There are millions of crawlers on the web. Some are very beneficial, and some facilitate spam, are failed experiments, or generally provide no value. Web pages also serve different purposes. Not all are intended to be crawled, and many organizations specifically don’t want their pages to be scraped. Note that without a Robots.txt or without a line in a Robots.txt file that relates to a crawling software you are using, that the default interpretation is that you are allowed to crawl this domain.
Unstructured Data isn’t necessarily entirely chaotic. It’s just data that’s not structured in such a way for each manipulation. Examples of unstructured data could include printed out business memos in different formats, or most web pages. Without thorough and precise extraction and transformation of this data, it’s hard to manipulate or take value from.
Structured Data doesn’t necessarily mean it’s entirely clean, accurate, or even neat. Rather, structured data just holds some form that makes it easier to consume programmatically. A great example of structured data is a spreadsheet or database. We all know that there are varying degrees to how “neat and tidy” both of these entities can be. But there is at the very least some semblance of metadata about what given values in fields “mean.”
Semantic data has long been hailed as the future of the web. While slow to roll out, web extraction companies like Diffbot help to take unstructured data and make it truly semantic. What is semantic data? Semantic data is data where the “meaning” of data is encoded alongside it. With this additional context, one can traverse a web of objects (or “entities”) to gain insight beyond simply reading descriptions.
The Four Routes To Extract Web Data
There are four primary routes most organizations choose for web data extraction. Each has trade-offs and provides separate levels of support, cost, and type of result. We’ll cover applicants of these four types of data extraction in ensuing sections related to your particular data extraction needs.
DIY extraction tools are tools that are geared towards non or semi-technical individuals who need to perform periodic extraction or would like to automate some – relatively – small scale data gathering job. Many of these tools utilize AI to attempt to detect what you want extracted from a given page. Many of these tools can be further tailored with some tool-specific knowledge or technical skills. Many of these tools provide intuitive UI’s and allow users to essentially click on what they want extracted.
Pros:
- Low barrier to entry
- Work “out of the box” for most major sites
- Low cost
Cons:
- Not good for wider crawls
- Often don’t work on smaller or oddly-structured sites
- Often can’t schedule crawls in advance to feed a data pipeline
- Not built for high-volume extraction
- Not very customizable
- Limited support
In-House Extraction utilizes the many open source or proprietary data extraction platforms that require some technical knowledge to get working. This work may be performed by a team of specialists, or a single knowledge worker depending on the complexity and scale of the operation. In-house extraction allows for total customizability of data streams, but often does lean on third-party platforms or softwares to provide the bedrock of web extraction efforts.
Pros:
- Good for high-volume crawling and extraction
- Can be completely customized
- Can be tailored to specialty, paywalled, and private sites
- You have complete control over extraction efforts
- There are many open source or reasonably-priced platforms to build off of
Cons:
- Requires technical expertise
- Needs configuration / doesn’t work right “out of the box”
- You may be your own support
- Can be cost intensive
Vertical-Specific Data Providers are brokers of data valued by a particular vertical. These data providers may be self service providers or provide customized data offerings for every client. Depending on the provider and nature of the data, it may be provided in a variety of structured forms or in PDFs, physical catalogs, or other historically prevalent forms. Additionally, these data providers may come in the form of “pre-tuned” scrapers that only work on a handful of sites. Say, social media group member scrapers.
Pros:
- Best choice for data not fully or readily available online
- Typically provide one “type” (subject matter) of data
- For some information more effective than developing scraping solutions
- Often provide APIs or Integrations to include in your reporting tools
Cons:
- Data available to competitors
- No control over when or how data is extracted
- Unlikely to cater to all of your data needs
- At the whim of non-transparent pricing and sourcing
Knowledge-As-A-Service Providers typically provide fully-functioning automated knowledge bases which provide contextually-aware data for a given discipline. These providers typically utilize AI or human-in-the-loop processes to constitute, ensure accuracy of, and grow their automated knowledge bases. One lens through which to view knowledge-as-a-service providers is that of a web extraction service that has “pre-extracted” large portions of the public web and constituted them into their own searchable databases or knowledge graphs.
While ten years ago a data focus might have manifested in curated data silos, the ensuing years have shown that non-automated data gathering, cleaning, and assessment can’t keep up with today’s needs. A decade ago data may have been claimed as the new oil. Today it’s viewed that way in a different sense: it’s expensive to store, useful until used, in a state of degradation unless maintained.
Pros:
- Potential for web-wide data unlikely to be achievable in-house
- Leaves customization of crawlers and extractors to the professionals
- Web data comes pre-structured saving time on data wrangling and sourcing
- Higher range of data leads to the ability to spot new opportunities for data use
- Low time/effort to obtain data for exploratory analysis
- Bypasses expensive data gathering and maintenance at scale
Cons:
- Some providers may have breadth but not depth for particular use cases
- You may need data about specific topics with greater frequency than Knowledge-As-A-Service providers update their data
- Complete overkill for some small data extraction jobs
Data Extraction Best Practices
As with everything, you’ll likely run into unforeseen issues if you’re new to data extraction. With that said, we’ve helped clients perform billions of extractions and have learned a thing or two along the way. Here are some best practices it’s worth being aware of as you start on your web extraction journey.
- Suss out data sourcing
- Define precisely what data is valuable for your org objectives
- Identify sources for the data you need
- Establish whether these sources can provide data with enough regularity for your org needs
- The best sources for predictable web data quality with minimal transforms are at least semi-structured
- Data governance definitions
- What sourcing, data lineage, or data provenance requirements do you have
- Regulations related to data storage or use of data
- Define business objectives supported by data
- Lay out data auditing practices
- Perform an initial small batch extract
- Don’t jump into big time data before you can profile how the data is likely to be returned
- Locate null or missing fields
- Quickly scan fields visually
- Make fields visual for macro inspection (histograms are great for this)
- Be respectful (or pay the price)
- Obey robots.txt
- Note that even if you scraped data that is public, you don’t necessarily own this data. Seek consent before re-publishing
- Don’t bulk or repeatedly scrape during peak business hours
- Don’t hit a site incessantly
How To Extract Data From One Page (Non-Technical)
DIY extraction tools are the route to pursue if you’re a non-technical individual looking to extract data from a single page.
These tools won’t scale well to pages of different types, and definitely not to different sites. But if you have a one-off process where you’re copying and pasting many entities from a single page, they can save you a great deal of time.
Pros:
- Cost effective (many times free)
- Small learning curve for tools
- Even extracting a single page can save you hours of time
Cons:
- Not scalable
- Data will not be “live”
- Few free tools provide access to data transforms
- Few free tools provide access to proxies
- Will still need to manually wrangle exported data in a spreadsheet or similar
Searching for “DIY web extraction tools” should yield a range of choices for this type of extraction. The two most available types of these tools include cloud-based providers and Google Chrome (browsers) plugins. For the sake of our demo, we’ll be utilizing import.io, which is largely representative of similar tools. If you prefer to use a browser plugin, webscraper.io’s Web Scraper browser extension is a trusted choice by many.
These tools typically allow users to load a page and click on elements representative of what they want extracted. Some tools employ AI to “guess” what you truly want extracted. While others rely on you clicking on elements that have some sort of underlying hierarchy to automatically produce scraping rules. For example, you may click on two headers within a document. Most DIY extraction tools will take this to mean that you want all headers extracted.
While the structure of web documents is beyond the scope of this section, it’s worth noting that “point and click” extractors tend to perform the best when you select elements with similar structure. Web documents are constituted of HTML elements that provide structure to a page. Common elements of this type may include:
- Paragraphs
- Bolded text
- Headers
- Links
- Images
- And so forth
Even without any detailed knowledge of HTML, selecting elements that perform the same function or are at the same level of visual hierarchy will in many cases lead to the data you want being selected.
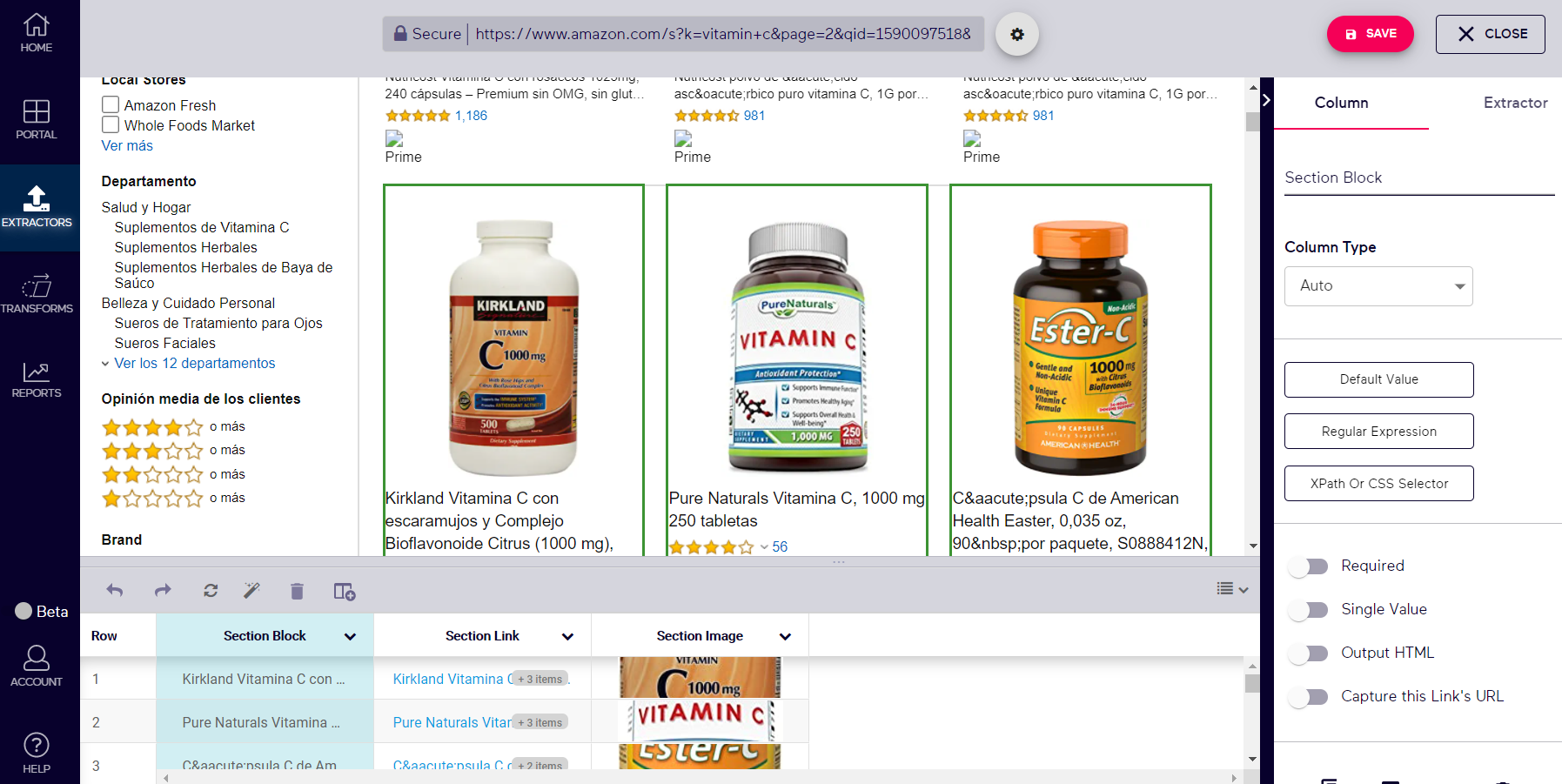
In the above example the green squares surround data that will be extracted from this Amazon product search results page. As Amazon is a well-known site, many DIY data extraction tools will automatically parse extracted data as one may expect. In this case Import.io knows to separate pricing, review data, links, and titles.
Using manual extractors or pointing AI-aided extractors at less common sites is likely to require selection of the elements you want.
Above we see a chrome extraction plugin that relies on manual input. In this case, selecting three titles led to the plugin selecting all non-sponsored titles for extraction. In manually-configured extractors users typically must input titles for columns and select which items on the page should populate this column (for csv or spreadsheet-ready formatted data).
How To Extract Data From One Page (Technical)
Technical individuals looking to extract data from a single page have two primary options: DIY extraction tools, or setting up a custom extraction script (in-house extraction).
Pros:
- Can employ a “trial run” of what will become a wider or more regular extraction
- Can export nested data types like JSON
- Can “roll you own” extraction via scripting language-based extractors
- Can employ more advanced selectors (regex or javascript-based)
- Largely customizable compared to non-technical single page extraction
Cons:
- Data wrangling and post extraction transforms add complexity to extractions
- Upkeep costs
For technical individuals utilizing DIY extraction tools like those detailed in the last section, typically a wider range of features are practicable, leading to enhanced extractions. Additionally, a wide range of API-based services as well as modules for scripting languages can accomplish single page extraction. This means that there are many, many more options for single page extraction even more moderately technical individuals.
Related Tutorial
Some elements worth considering when choosing a single-page extraction service include:
- The regularity with which you would like to extract single-page data
- Whether or not the ability to perform automated transforms on extracted data is important
- Whether or not “future proofing” by choosing a service that could be scheduled or applied to many pages is important
DIY Extraction Tools can be utilized similarly to how they are described in the last section. Of note, many DIY extraction tools do provide more advanced features that allow you to tackle particularly messy or unique pages you’re seeking to extract.
The most routinely available and utilized advanced DIY extraction features for single page extractions include:
- The ability to use pattern matching such as regular expressions to specify what you want to extract
- The ability to insert javascript into the head of the rendered page to automatically perform some interactivity or transform on data on the page
More custom in-house extraction may be “overkill” for many single page extractions. But with moderate technical know-how can also lead to cost effective and automatable extractions via common scripting languages or API access to extraction services. One consideration is that if you plan to expand your extraction efforts to many pages, that custom extraction rules often become the single largest addition to upkeep costs. This applies to single-page extraction as well. But typically only in the event that the desired page is dynamic or dramatically updated with any regularity.
Choosing an in-house extraction method for in-house extraction there are typically two routes a technical team could pursue:
- API-based extraction services
- Scripting language-based extraction
The primary trade-offs of these two routes include subscription costs, customizability, and upkeep costs.
Related Tutorial
API-based extraction services are typically subscription based. Scripting language-based extraction is often open source. Scripting language-based extraction is more customizable. But also requires upkeep, potential management of proxies, and data may still need to be wrangled. API-based extraction services will in a large majority of cases continue to work even when the page to be extracted is dramatically altered in structure.
We’ll work through quick examples of both of these methods. An example of API-based extraction services can be found on Diffbot’s Automatic Extraction API page or in the video tutorial above.
API-based extraction typically involves the passing of a url as well as parameters to specify what you would like returned after extraction has occurred. Many API-based extraction are AI-enabled to provide the extractor with the best possible chances of extracting the desired information with minimal human input.
In the case of Diffbot’s automatic extraction APIs, individuals can point different APIs at different types of pages. These page / API types include:
- All page types / the Analyze API
- Article page types / the Article API
- Discussion data / the Discussion API
- Image-heavy pages / the Image API
- Product pages / the Product API
- Video-centered pages / the Video API
Some of the largest benefits of API-enabled extraction include the ability to programmatically control or trigger your extraction as well as the ability to crawl on scale. While we’re just talking about single page crawls in this section, it’s worth noting that using API-enabled extraction services helps to “future proof” your extraction in the event you wanted to scale it to more pages.
If you’re extracting a well known and well structured site, API-enabled extraction can also be one of the simplest ways to extract a page. For example, an API call Diffbot’s Article API being passed an article from the NYTimes could be as simple as the following line:
Which would return something like the following response:
Scripting language-based extraction can be easily achieved through nearly any language that can make a post request to a server. With that said, there are a few front runners due to large community size as well as ease of manipulating returned data.
Notably, some of the most popular scripting language-based extraction libraries include:
- Python
- Scrapy
- BeautifulSoup
- Selenium
- Ruby
- Nokogiri
- Node.js
- Axios and Cheerio NPM Modules
There are pros and cons to each of the three scripting languages above. But if you’re going to use a scripting language for extraction, the primary consideration should be what language you’re most comfortable with and that best fits your objectives for how the extracted data will be utilized.
Choosing to pursue a scripting language-based extraction method can be one of the quickest ways to get up and running assuming you have a working knowledge of the scripting language at hand. It also provides the greatest flexibility. BUT, it’s a fully custom extraction. This means that you’ll need to hard code each element you want extracted from a page. And then you’ll have to validate, organize, and place that data into a format for processing.
Above is an example of a simple script for grabbing related post links from a NYTimes article. There’s not too much to it. And assuming the css selectors are properly set (and the site doesn’t change it’s structure), you should be able to continue running this pointed at different pages or the same page over time.
The real trade off occurs once the raw extracted data is passed into the data lifecycle. To enhance a script like that above to actually provide valuable data, you’ll at the very least need to add some context such as the name of post being extracted from, the date, the author, potentially category tags and more. If you’re extracting large swaths of a page, formatting may become an issue as well. Repairing unfortunately formatted extraction output with pattern matching has the propensity to become an upkeep nightmare. On the other hand, all common scripting languages are free and your extraction can be infinitely customizable.
How To Extract Data From An Entire Site (Non-Technical)
Non-technical individuals looking to extract data from an entire site should likely utilize a knowledge-as-a-service platform or vertical-specific data provider.
Even the smallest sites can have a range of page types, each of which would need to be classified and approached with custom extraction rules for more hands-on or DIY extraction methods to work.
The cost in man hours and potential need to pull in technical assistance anyway quickly range above the costs of most knowledge-as-a-service or vertical-specific data providers.
Perhaps the most important questions that can point you to one or the other of these options include:
- Exactly what type of data do you need from an entire site?
- Is it more than one type of data?
- Do you truly need to extract the whole site, or a subset of pages?
If you need one type of data, say data on products on Amazon, or data on backlinks, it’s likely there’s an extraction-centered service that already caters to this need. If, however, you want multiple data types from across a site, a knowledge-as-a-service provider is likelier to be your best bet. If you find that you truly only need a handful of pages – depending on the number – you could follow steps similar to those outlined in the section on extracting from a single page (non-technical).
Vertical-specific data providers
include the likes of Ahrefs, Alexa, and SEMRush in marketing settings. Buzzsumo and
Traackr provide best-in-class influencer tracking. And there are a wide range of ecommerce specific extractors for the likes of shopify sites or Amazon.
A host of tutorials are available for all of these services. So we won’t jump into those topics here. The important thing to remember is that it’s important to clarify exactly what type(s) of data you’re seeking to pull from a site during a site wide extraction. If your answer is product details, you should likely be looking for a product scraper. If it’s backlink data then a marketing data tool is where you should look.
The most common types of data individuals find valuable extracted from an entire site include:
- Product and pricing data
- Marketing, SEO, and PPC stats about a site
- The raw content
- List of tags, categories, or authors
If you find you want a range of these data types – particularly over many pages – you will likely want a knowledge-as-a-service provider who can provide some additional context to each individual data type.
So what exactly do we mean by knowledge-as-a-service?
In relation to data extraction, knowledge-as-a-service providers typically provide more than just the data from a given page. As described in the DIKW (data, information, knowledge, wisdom) pyramid. Each level of the pyramid is a function of the lower. Data with context is information. Information with “experience” is knowledge. We won’t get into what true wisdom is here…
Knowledge-as-a-service centered around data extraction typically factors in this additional “experience” to provide cross-site data that is valuable for organizational goals. This “experience” is often applied through machine learning approaches to extraction and parsing.
In the case of Diffbot, we use machine vision and natural language processing to pull meaning from pages. We then fuse individual facts into “entities” such as organizations, people, skills, articles, tags, and so forth. These entities are interlinked and mimic the way we actually think about elements in the world. This organization of a site into “things” instead of plain text is essentially the application of experience that enables “knowledge” in the DIKW pyramid.
While your options for extracting sitewide data are greatly limited as a non-technical user, you do have some options for extracting sitewide data. With a little knowledge of crawl-specific terminology you can get a sitewide crawl and data parsing going in a matter of minutes with Diffbot’s Crawlbot.
Related Tutorial
Crawlbot works by selecting seed URLs. Unless otherwise specified, the crawler will follow every internal link from every seed URL. You wrangle which pages you want to crawl by specifying two values:
- Crawl patterns dictate which links you want your crawler to follow on a site. For example, you may want to grab every product page by specifying /products should be in every followed link URL.
- Processing patterns dictate which crawled pages you then want to process using one of Diffbot’s Automatic Extraction APIs.
While Diffbot’s Automatic Extraction APIs may sound technical, implementation through Crawlbot is actually beginner friendly. Each API is trained to extract a certain type of data from pages on which that data is present. For example, the article API extracts information you would expect to find in an article. This could be author, categories, article text, and publication date. The Product API is trained to extract the most common fields on product pages. These could include availability of products, their URL, their price, their sale price, their review data, shipping specifications, and more.
While you are utilizing an API (application programming interface) when you use Crawlbot, you don’t actually need to know how to program.
Simply select the API you want to parse the given domain with and watch the results pour in!
Note that data can be returned as JSON to be consumed by an application, or in the less-technical user friendly format of CSV. The above job crawled every page on iHerb.com that contained a Manuka Honey-Related product without using one line of code!
How To Extract Data From An Entire Site (Technical)
Technical users have a wide range of options for extracting data from an entire site. Typically speaking, you’ll need to utilize two types of technologies to pull off a full site crawl.
- Spidering or crawling software follows links throughout a site given a particular pattern of URLs to follow.
- Web extraction frameworks pull specific pieces of data from pages given a URL
There are presently no roll-your-own Python or Javascript web extraction libraries that perform both of the above tasks. So you’ll need to find a spidering tool that you can then pass the results from to a web extraction library.
An additional consideration when building your own site-wide scraping script is that of speed. Python libraries like Selenium visually load every page to be extracted from which can take noteworthy amounts of time when dealing with large sites.
With Diffbot you can perform both the initial spidering and then extraction from individual pages utilizing our Crawlbot paired with an Automatic Extraction or Custom Extraction API. We worked through a basic version of this in the prior section of this document.
You can find a more fully-fleshed out example in the following video comparing Python web extraction methods.
Related Tutorial
Diffbot’s Automatic Extraction APIs allow for rule-less extraction that will be applied to each spidered page (what Crawlbot does) on a domain. For many page types including articles, products, and discussions, Automatic Extraction APIs just work right out of the box. If you want a specific piece of information returned, you may need to create a custom API. You can create a custom API by specifying a test domain and name for your crawler
here.
You can then specify what fields you want returned from your sample domain by visually selecting elements on the test domain or specifying what to return via CSS selectors or regex.
While this process is similar to other extractors including Import.io, Octoparse, and Chrome browser plugins, the primary difference is that Diffbot’s Custom Extraction APIs can be applied site wide utilizing Crawlbot.
Smart spidering using Crawlbot is a particularly powerful tool as you can crawl 10 pages or 10 million, all of which will be loaded remotely (not on your machine) and can have the same custom or standard fields extracted from them. One note is that crawling and processing patterns within Crawlbot can dramatically lower or raise the amount of time your crawl will take. Try to be as specific as you can by sussing out patterns in the URLs you would like data from.
How To Extract Data From Across The Web (Non-Technical)
If you can extract data from across an entire domain, you should in theory be able to repeat this process over many sites. Perhaps you have a digital portfolio of 10 or 100 sites. And while the process for extracting data across sites is typically just the process of extracting across a single domain repeatedly, many of the major issues with full site extraction are magnified when extracting from multiple sources.
In particular, the following issues play a larger role in multi-site extraction:
- Increased risk of having your IP address banned
- Increased risk of one or several web scrapers breaking due to site changes
- Holes in data coverage due to site or web scraper outages
- Just more moving parts that
While utilizing Diffbot’s Crawlbot repeatedly across a range of sites is an option for non-technical web data extractors, the complexities of scaling and merging results from many domains may quickly get daunting.
This is where Knowledge-as-a-service providers come into play. Knowledge-as-a-service providers typically play the role of not only amalgamating many knowledge sources, but ensuring data extraction from these sources scales, data is standardized, and you as the end user can simply explore whatever domain of knowledge is provided. There are a handful of options available depending on what sort of data you wish to have extracted.
Related Content
Knowledge-As-A-Service Zapier Integration Providing Lead Data Enrichment From Public Web Data
For people and contact data, a range of options are available including publicly scraped contact data (such as Hunter.io) or data obtained through other means (such as Clearbit or ZoomInfo). Diffbot also offers organizational and people-centered data enrichment through our Enhance product which is a fraction of the price of Clearbit or Zoominfo, and competitively priced with Hunter.io. The inclusion of both organizational and person data enrichment via Enhance is nice because important data can be at the organizational or person level.
If you’re looking for marketing-centered information, a host of providers including Ahrefs, Semrush, and others can help inform your SEO and PPC campaigns with data from across the web. Typically this data is limited to keywords, search engine placement results (SERPs), the average cost for ads, and other marketing data.
For a rundown comparing Diffbot to several other web-wide crawling knowledge-as-a-service providers, check out our guides comparing Diffbot and GDELT (another knowledge graph provider focusing on social movements), and our comparison of Alexa, Ahrefs, and Diffbot.
If you’re looking for a myriad of information types, Knowledge Graphs such as Diffbot’s Knowledge Graph or the GDELT project may be what you’re looking for. These providers crawl large swaths of the web and consolidate facts found online into knowledge graph entity types.
Of the two Knowledge Graph providers listed a primary difference is that GDELT focuses on geopolitically important events, while Diffbot tracks a wide variety of site types and most notably online presences of organizations, people, products, articles, and discussions.
While some web-wide extractions will require a custom set up, typically the crux of this process for individals consuming knowledge-as-a-service providers is properly integrating these data streams with your own applications. Even if you have a web’s worth of data, the “last mile” problem can be very troublesome and you’ll want to spend time considering how to best consume the data streams and get data in front of actual end users.
How To Extract Data From Across The Web (Technical)
One of the hardest problems to solve with web scraping at scale is that you don’t know what a given page will look like until you encounter it. Rule-based scrapers that work on one site are almost guaranteed to fail on others. And even keeping rule-based extractors routinely working on a handful of sites through site updates can be a job.
What this means is that to truly have a claim to crawling the web you’ll need to escape the rigidity and minutea of rule-based extraction. Rule-less extraction typically utilizes natural language processing, machine vision, and more generally AI-based solutions to extracting valuable information.
Note: one instance in which ruleless extraction may not be necessary to crawl across the web is if you’re looking for the exact same set of elements across many pages. For example, you’re writing a crawler to track backlinks.
In the following video Diffbot’s founder and CEO Mike Tung outlines – at a high level – how Diffbot extracts and strctures web-wide data into the world’s largest Knowledge Graph.
Web Scraping Legality
At its simplest, web scraping is simply automating the act of browsing through a public web page and recording some set of elements. Just as it would be legal to manually work through a site, recording values into a spreadsheet, so too is it legal to work through the same pages with a more efficient system.
With this said, a few additional factors come into play when web scraping at scale. Just as it is legal for you to browse through a public web page and extract data, so too is it legal for web page providers to change their content, block you from their content, and blacklist your IP address for a host of reasons. Most pages of any size include rules against accessing their site in ways it was not intended to be in their terms and service conditions. The most prevalent form of this sort of policing of how you access content is in the form of the robots.txt file.
Robots.txt files dictate which pages should or should not be crawled on a domain. These are used by site managers to primarily point search engine crawlers towards important pages. Robots.txt can also specify which crawlers are allowed on a site, how frequently crawls should occur, and so forth. It’s best practice to look at the robots.txt file of a site before crawling, if for no other reason than to gain an understanding of what sorts of crawling patterns the site managers don’t like.
While not technically a matter of legality, using common sense and respecting site bandwidth is a good way to not get banned from future crawls. If you’re performing particularly large crawls or with regularity, try not to crawl during peak visitor hours for the site. Try say, crawling in the middle of the night. Rate limit crawls. Even just a few seconds between pinged domains can make a great deal of difference at scale and leave service unaffected by others.
All of this is to say that web scraping is legal and an integral part of many services that enable us to explore the web today. Just use common sense and be courteous to sites being scraped so as not to disrupt service or overload a site.



