tutorials
We Built an Automated Sanctions Tracker in One Week
As of March 21st 2022, we've tracked at least 602 companies from 50 countries who've announced sanctions in response to Russia's invasion of Ukraine. This guide will show you how to build one yourself.
Last Updated: April 09, 2024
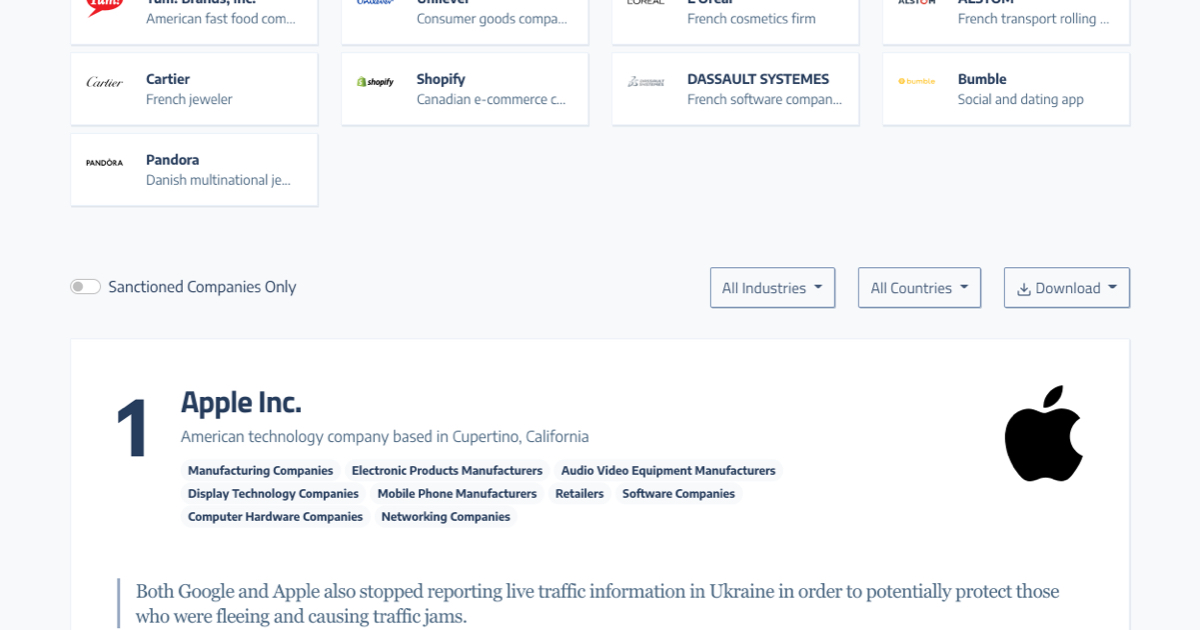
As of March 21st 2022, we’ve tracked at least 602 companies from 50 countries who’ve announced sanctions in response to Russia’s invasion of Ukraine, led by president Vladimir Putin.
I say “at least” because this figure might not represent every company sanction in the world, but it is definitively the most comprehensive, fully cited collection available today.
It operates autonomously and doesn’t require any manual updates to refresh the data each day.
Instead of a team of analysts, we employ Natural Language Processing (NLP) and train a text classification ML model to identify sanctions reported in the news.
Sound complicated? It can be, but with Diffbot Knowledge Graph and Natural Language Processing, we can abstract away the complexity of gathering news data and identifying companies. What’s left is the relatively simple step of training a classifier to recognize sanctions.
In fact, you can build one yourself. This step by step tutorial will show you how, and only requires basic Python experience to follow and understand.
Here’s everything I will cover:
- Step 1 — Get News, our raw source of sanction statements
- Step 2 — Identify Organizations mentioned in each news article
- Step 3 — Train a Classifier to Identify Sanctions
- Step 4 — Use the Classifier to Predict Sanctions
Keep in mind, identifying sanctions is only one use case. This same method can be extended to identify any kind of signal from the news. And since this script can be put on autopilot, you only ever have to build it once to reap the benefits forever.
Prefer to jump right into the code? Here you go.
Requirements
- Python 3.8+
- Diffbot API token (get a free token here)
Step 1 — Get News
We need a source of sanctions. News is a fantastic source. Publications can be vetted for reliability, and raw text is surprisingly easy to structure with modern NLP tools.
Major news publishers will curate manual lists that are fairly clean, but since they take a lot of work to curate, major publishers may also stop updating these lists once sanctions stop becoming breaking news.
Instead of relying on a single source, a more bulletproof approach is to source from every reliable news source on the internet.
This is easily done with Diffbot’s Knowledge Graph, which is constantly refreshing its Article data with quality vetted breaking news, press releases, and blog posts from the web. This option also allows us to skip the crawling, scraping, and cleaning steps typical of crawling web data.
A simple query (DQL) for articles in the Knowledge Graph published in the last 30 days looks like this:
type:Article date<30d sortBy:date
Here’s how it looks plugged into a GET call:
https://kg.diffbot.com/kg/v3/dql?type=query&token=YOURTOKENHERE&format=jsonl&query=type%3AArticle+date%3C30d+sortBy%3Adate
This call returns a JSONL response that looks like this:
{
"data": [
{
"summary": "Az 5G nem csupán egy ráncfelvarrás, egy egyszerű frissítés a vezeték nélküli hálózatok technológiájá...",
"image": "http://hirek.prim.hu/download/viewattach/140798/2/115/1465790-2010756248.jpg",
"types": [...],
"images": [...],
"diffbotUri": "http://diffbot.com/entity/ART68569801557",
"publisherRegion": "Hungary",
"icon": "http://hirek.prim.hu/favicon.ico",
"siteName": "Prim Online",
"language": "hu",
"type": "Article",
"title": "A Dell Európában is elérhetővé tette az 5G-képes Dell Latitude 9510 modellt",
"tags": [...],
"lastCrawlTime": 1634766977,
"publisherCountry": "Hungary",
"name": "A Dell Európában is elérhetővé tette az 5G-képes Dell Latitude 9510 modellt",
"pageUrl": "http://hirek.prim.hu/cikk-proxy/a_dell_europaban_is_elerhetove_tette_az_5g-kepes_dell_latitude_9510_modellt",
"html": "...",
"id": "ART68569801557",
"text": "...",
"resolvedPageUrl": "http://hirek.prim.hu/cikk/a_dell_europaban_is_elerhetove_tette_az_5g-kepes_dell_latitude_9510_modellt"
}
...
]
}
It’s possible to process every article for sanctions, but with some smart prefiltering we can dramatically increase the speed and efficiency of our sanctions tracker.
A simple starting point is to query for articles that mention Russia and/or Ukraine from the day Russia invaded Ukraine.
type:Article text:or("Russia", "Ukraine") date>"2022-02-23"
This is far too broad of course. Let’s filter it down by also querying for common phrases used to describe sanctions.
type:Article text:or("Russia", "Ukraine") title:or("sanction", "sanctions", "sanctioned", "sanctioning", "pulled out", "pulling out", "pulls out", "suspended", "suspending", "suspends", "stopped", "stopping", "halted", "halting", "restricted", "restricting", "closes", "close", "shuts down") date>"2022-02-23"
And for a little quality of life measure, we’ll sort it all by date.
type:Article text:or("Russia", "Ukraine") title:or("sanction", "sanctions", "sanctioned", "sanctioning", "pulled out", "pulling out", "pulls out", "suspended", "suspending", "suspends", "stopped", "stopping", "halted", "halting", "restricted", "restricting", "closes", "close", "shuts down") date>"2022-02-23" sortBy:date
# 24,124 Results. First 5 Titles:
# "Germany faces recession if oil & gas halted, say banks"
# "Tougher Russia sanctions urged over Ukraine ‘war crimes’"
# "US to announce new sanctions against Russia this week"
# "Stocks, dollar rise; European leaders urge further Moscow sanctions"
# "Ukraine war, chance of more sanctions on Russia lift gold's appeal"
This is looking really good. Let’s wrap up this step with a Python script to download all 24,000 articles into a file called articles.jsonl.
import urllib
import urllib.parse
import subprocess
token = "YOUR DIFFBOT TOKEN"
# Generate a simple GET request for the articles
def createQueryUrl(dqlQuery, size=50):
url = "https://kg.diffbot.com" + \
"/kg/v3/dql?token="+token+"&type=query&format=jsonl&size=" + str(size) + \
"&query=" + urllib.parse.quote_plus(dqlQuery)
print(url)
return url
# DQL Query for the articles we want in the Diffbot KG
query = 'type:Article text:or("Russia", "Ukraine") title:or("sanction", "sanctions", "sanctioned", "sanctioning", "pulled out", "pulling out", "pulls out", "suspended", "suspending", "suspends", "stopped", "stopping", "halted", "halting", "restricted", "restricting", "closes", "close", "shuts down") date>"2022-02-23" sortBy:date'
# Save it all in a file called articles.jsonl
p = subprocess.run(['wget', '-O', "articles.jsonl", createQueryUrl(query, 1000000)])
if p.returncode != 0:
print("Something went wrong")
Step 2 — Identify Organizations
With over 20,000 articles in hand, we’re ready to start processing. We want the final result to be a list of companies, so let’s start with identifying organizations mentioned in these news articles.
Finding organization names sounds straightforward. We can just use a Named Entity Recognition (NER) system to find organization names in the article. There are several options, both open-source (Spacy, GATE Annie) and commercial offerings (Google, IBM Watson).
But wait, what if an organization is known by different names (e.g., WarnerMedia vs. Time Warner)? What about ambiguous names (e.g., Apple) and names in different languages (e.g., Сбербанк / Sberbank)? How can we make sure we are correctly identifying the correct organization in the real world?
This is where the Diffbot Natural Language API (NL API) can help. The NL API not only recognizes organization names in text, it also returns a link to this organization entry in the Diffbot Knowledge Graph.
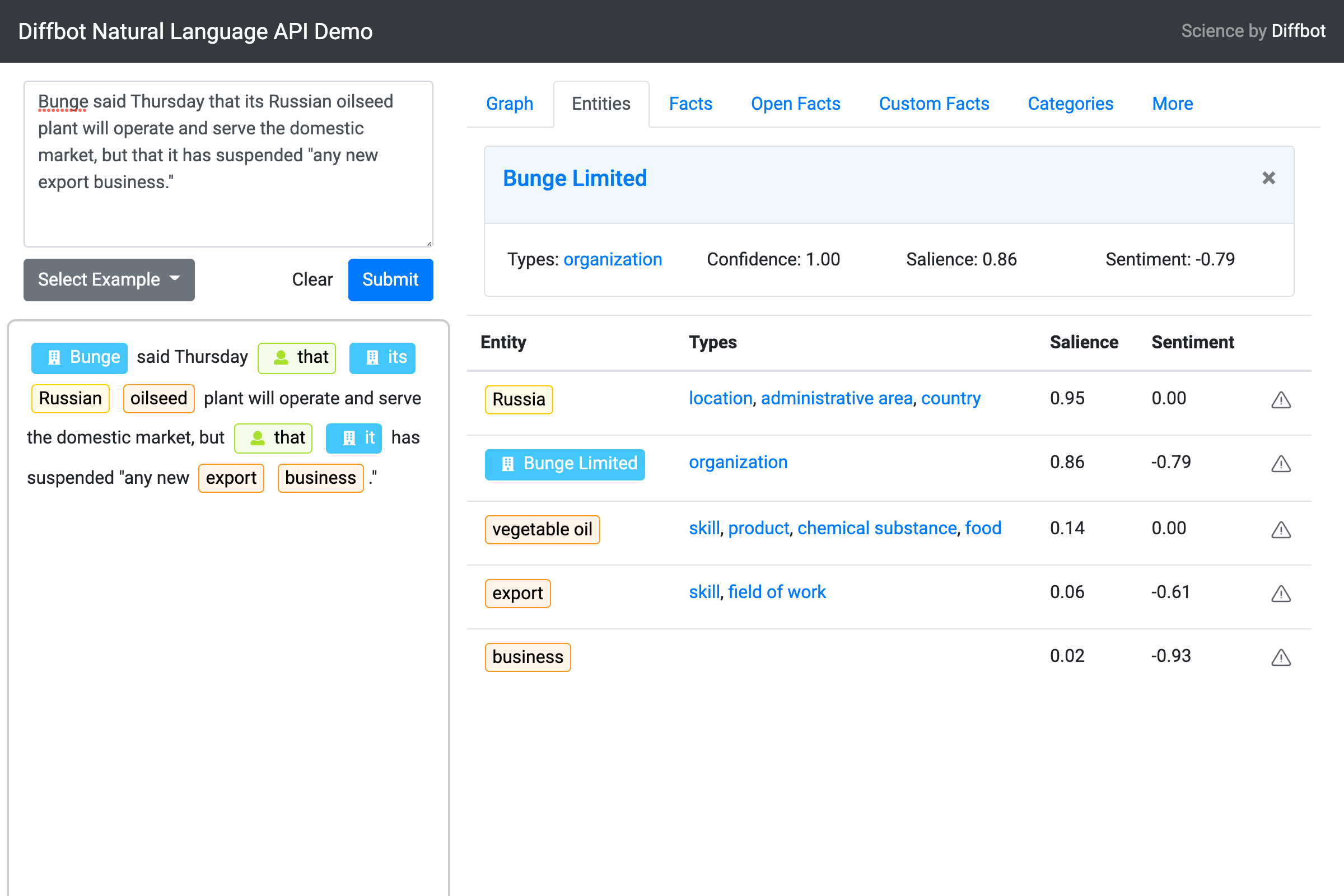
Moreover, the NL API also does something extra special — linking the pronoun “it” to the subject “Bunge”, a feature known as coreference resolution.
This allows us to explicitly tie individual facts to the correct subject entity.
If the statement were written
Bunge, unlike oilfield services company Schlumberger, said Thursday that its Russian oilseed plant will operate and serve the domestic market, but that it has suspended “any new export business.”
Diffbot NLP would have no trouble disambiguating Bunge from Schlumberger as the correct subject entity that is “suspending new export business”.
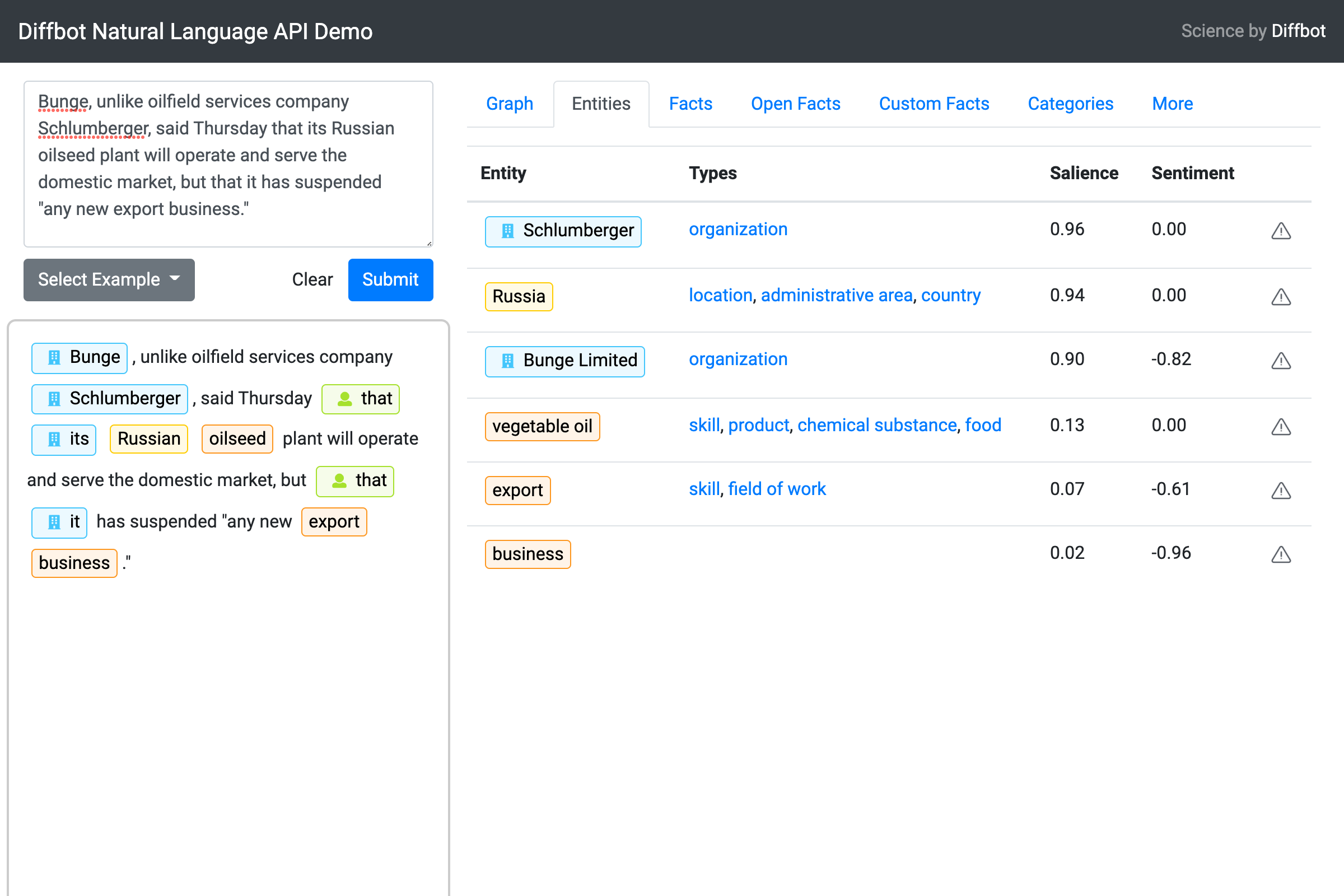
Good to know for the adventurous among you maximizing accuracy, but to keep things simple, we’ll stick with analyzing sentences for this guide.
Let’s start with a simple NLP API call on our example statement.
import requests
statement = "Bunge, which has assets of $121 million in Russia, said Thursday that its Russian oilseed plant will operate and serve the domestic market, but that it has suspended 'any new export business.'"
TOKEN = "<ENTER DIFFBOT TOKEN>"
payload = {
"content": statement,
"format" : "plain text",
"lang": "en",
}
fields = "entities, openFacts, sentences"
res = requests.post("https://nl.diffbot.com/v1/?fields={}&token={}".format(fields, TOKEN), json=payload, timeout=120)
ret = res.json()
print(ret)
Which will return this JSON response
{
"entities": [
...
{
"name": "Bunge Limited",
"diffbotUri": "https://diffbot.com/entity/EGEM-XkioOh2Mgrt0DixG_A",
"confidence": 0.99993026,
"salience": 0.8726607,
"isCustom": false,
"allUris": [
"http://www.wikidata.org/entity/Q1009458"
],
"allTypes": [
{
"name": "organization",
"diffbotUri": "https://diffbot.com/entity/EN1ClYEdMMQCxB6AWTkT3mA",
"dbpediaUri": "http://dbpedia.org/ontology/Organisation"
}
],
"mentions": [
{
"text": "Bunge",
"beginOffset": 0,
"endOffset": 5,
"confidence": 0.98744655
},
{
"text": "its",
"beginOffset": 70,
"endOffset": 73,
"isPronoun": true,
"confidence": 0.99984443
},
{
"text": "it",
"beginOffset": 149,
"endOffset": 151,
"isPronoun": true,
"confidence": 0.99993026
}
],
"location": {
"latitude": 51.509647,
"longitude": -0.099076,
"precision": 39.86554
}
},
...
],
"openFacts": [
...
{
"humanReadable": "<it> has suspended ' any new <export> business",
"firstEntity": {
"name": "Bunge Limited",
"diffbotUri": "https://diffbot.com/entity/EGEM-XkioOh2Mgrt0DixG_A"
},
"openProperty": "has suspended ' any new <2> business",
"secondEntity": {
"name": "export",
"diffbotUri": "https://diffbot.com/entity/E1f7uO68mMbqusqI1KNqqPw"
},
"confidence": 0.99,
"readability": 0.94973105,
"evidence": [
{
"passage": "Bunge, which has assets of $121 million in Russia, said Thursday that its Russian oilseed plant will operate and serve the domestic market, but that it has suspended 'any new export business.'",
"entityMentions": [
{
"text": "it",
"beginOffset": 149,
"endOffset": 151,
"isPronoun": true,
"confidence": 0.99993026
}
],
"valueMentions": [
{
"text": "export",
"beginOffset": 175,
"endOffset": 181,
"confidence": 0.8533652
}
]
}
]
},
...
],
"sentences": [
{
"beginOffset": 0,
"endOffset": 192
}
]
}
Notice that each mention of an organization comes with a beginOffset and endOffset value. This will come in handy later to exact the exact sentence referencing an organization and their associated sanction.
We’ll run each article through Diffbot NLP the same way.
import sys
import json
import requests
from multiprocessing import Pool
# Generates a single Diffbot NLP request
def callNaturalLanguage(payload, fields):
# Progress Meter, this will take awhile
print(".", end="", flush=True)
ret = None
try:
res = None
res = requests.post("https://nl.diffbot.com/v1/?fields={}&token={}".format(fields, TOKEN), json=payload, timeout=120)
ret = res.json()
except requests.Timeout as err:
print("\nRequest timeout for payload:\n" + json.dumps(payload) + "\n")
except:
print("\nError for payload: " + json.dumps(payload) + "\n")
if res:
print("\nBad response: " + res.text + "\n")
return ret
# Calls Natural Language API on each article
def processArticle(article):
title = article.get('title', '')
text = article.get('text', '')
article['naturalLanguage'] = callNaturalLanguage({
"content": title+"\n\n"+text,
"format" : "plain text with title",
"lang": "en",
}, "entities, facts, sentences")
return article
articles = []
# Loop through each article in articles.jsonl
with open("articles.jsonl", "r") as f:
for line in f:
article = json.loads(line)
# truncate articles that are too long
if 'text' in article and len(article['text']) > 10000:
article['text'] = article['text'][0:10000]
articles.append(article)
# Pararellize the requests to Diffbot NLP to speed things up
with Pool(50) as p:
res = p.map(processArticle, articles)
# Save the NL processed data in facts.jsonl
with open("facts.jsonl", "w") as nl:
for article in res:
nl.write(json.dumps(article) + "\n")
Once we save and run this script as 2_call_nl.py, we should now have a folder with the following files:
1_get_articles.py
2_call_ny.py
articles.jsonl
facts.jsonl
Step 3 — Train a Classifier to Identify Sanctions
For every sentence that mentions an organization in the 20,000+ articles we downloaded, we want to know if this is a statement about a sanction, or something else entirely.
For example, this is a sanction statement:
Heineken and Carlsberg have stopped sales of their namesake leading brands in Russia and ring-fenced their Russian operations.
This is not:
France’s Renault, which controls Russian car maker Avtovaz, fell 9.3 per cent.
There aren’t any surefire rules we can apply to tell when a statement is a sanction. But as a human, we’ve acquired a lifetime of pattern recognition and language sense to tell the difference instantly.
Thankfully, a machine learning classifier doesn’t need a lifetime of pattern recognition to work, but it does require a bit of training to learn what’s a sanction and what isn’t. For this tracker, we will use an open-source machine learning library called fasttext. This library might not achieve the highest possible accuracy, but it is simple and fast to use for someone like me (not a data scientist). If optimal accuracy is critical for your application, give my team a shout, we’d be happy to help.
A typical workflow would start with preparing a list of sentences, then labeling some of these sentences manually as either false (negative example) for “not a sanction” or true (positive example) for “is a sanction”.
Some of these labeled sentences will be used to train the classifier, and the rest will be used to measure how well the classifier does. Once we are satisfied with the performance of the classifier, we can let the classifier loose on the rest of our sentences.
As you might imagine, labeling sentences is going to take some effort. However, we can take some shortcuts to help ease the work of labeling sanction statements.
Instead of starting with sentences, we start with organizations that we are certain are or are not involved in sanctions. We then use this list to automatically label sentences. By doing this, we were able to quickle annotate thousands of sentences. Here’s how it comes together:
- Seed a short list of organizations that we are certain have or have not announced sanctions.
- Use all sentences mentioning an organization NOT involved in sanctions as negative examples
- Include a sentence mentioning an organization known to be involved in sanctions as a positive example only if this sentence includes a keyword related to sanctions. This extra step is needed since not all sentences mentioning this organization will do so in the context of sanctions.
We can seed our short list of organizations by starting from existing sanctions datasets like the few mentioned earlier. If you’re building this tracker from scratch, start with 20ish organizations. We can always add more labels later. Otherwise, feel free to borrow our seed list of 300 organizations here.
This is what the seed list should look like as a TSV file.
diffbotUri name ground_truth
https://diffbot.com/entity/EHb0_0NEcMwyY8b083taTTw Apple Inc. TRUE
https://diffbot.com/entity/EUFq-3WlpNsq0pvfUYWXOEA GOOGLE INC. TRUE
https://diffbot.com/entity/EZ6w9akSkPweYBTenCPb46Q Visa Inc. TRUE
https://diffbot.com/entity/EIsFKrN_ZNLSWsvxdQfWutQ Microsoft Corporation TRUE
https://diffbot.com/entity/EMXpivoUwMd-E24rrNKMydQ TUI AG FALSE
https://diffbot.com/entity/EQPFMqc1jPHufdvSTLirQrA Oriental Trading Company FALSE
https://diffbot.com/entity/EluisPVnnNcGbFrFE_s2rYw SpaceX FALSE
...
Note that we’ve used an identifier called diffbotUri as it is much more consistent than referencing name. Conveniently, since Diffbot NLP links identified organizations to a diffbotUri, getting firmographics later is a simple diffbotUri lookup request.
We’ll save all this as ground_truth.tsv.
Once you have the file saved, let’s load it up into a dict.
ground_truth = {} #diffbotUri -> boolean (positive or negative example)
with open("ground_truth.tsv") as gt:
for line in gt:
line = line.strip()
fields = line.split("\t")
if len(fields) < 3:
continue
if len(fields[0]) == 0:
continue #missing uri
if len(fields[2]) == 0:
continue # missing label
uri = fields[0]
diffbotId = uri[uri.rfind("/")+1:]
uri = "https://diffbot.com/entity/" + diffbotId
ground_truth[uri] = {"name":fields[1], "label":fields[2] == "TRUE"}
Next, we’ll pull up our trusty facts.jsonl file and isolate sentences by recognized organizations and sanction keywords.
import json
import random
def force_https(url):
return url.replace("http://", "https://")
sentences = {}
random.seed(77777)
with open("facts.jsonl", "r") as f:
for line in f:
doc = json.loads(line)
content = doc["title"]+"\n\n"+doc["text"]
nl = doc.get('naturalLanguage', None) # Load up all the NLP labels we've saved
if nl and nl != None and 'entities' in nl:
for entity in nl['entities']:
if "diffbotUri" not in entity: # Ensure we have an identifier
continue
entity["diffbotUri"] = force_https(entity["diffbotUri"])
if entity['diffbotUri'] not in ground_truth: # Look for entities we know
continue
label = ground_truth[entity["diffbotUri"]]["label"]
validation = random.random()>0.8 # 80% of organizations are used for validation only
for mention in entity["mentions"]:
mentionBegin = mention["beginOffset"]
mentionEnd = mention["endOffset"]
for sent in nl["sentences"]:
if mentionBegin >= sent["beginOffset"] and mentionBegin < sent["endOffset"]: # Ensure organization is mentioned in the sentence
sent_text = content[sent["beginOffset"]:sent["endOffset"]]
if "\n" in sent_text or "\t" in sent_text or len(sent_text) < 50:
continue
after = content[mentionEnd:min(sent["endOffset"],mentionEnd + 30)].lower()
after = " " + after + " "
before = content[max(0,mentionBegin - 10):mentionBegin].lower()
before = " " + before + " "
keywords = ["disconnect", "disconnects", "disconnected", "disconnecting",
"pause", "pauses", "paused", "pausing",
"block", "blocks", "blocked", "blocking",
"sanction", "sanctions", "sanctioned", "sanctioning",
"halt", "halts", "halting", "halted",
"suspend", "suspends", "suspended", "suspending",
"to stop", "stops", "stopped", "stopping",
"prohibit", "prohibits", "prohibited", "prohibiting",
"remove", "removed", "removing",
"no-fly", "no fly",
"to leave", "leaving", "left", "leaves",
"to cancel", "cancels", "cancelling", "cancelled",
"to close", "closes", "closed", "closing",
"shut down", "shuts down", "shutting down", "shutted down",
"restrict", "restricts", "restricted", "restricting",
"pulling out", "pulled out", "pulls out", "pulls out",
"withdrew", "withdraw", "withdraws", "withdrawing",
"cease", "ceasing", "ceased", "ceases",
"barred", "no longer",
"exclude", "excluded", "excluding", "excludes",
"blacklisting", "blacklist", "blacklists", "blacklisted"]
foundKeyword = False
for k in keywords:
if re.match(r".*\b"+k+r"\b.*", before + " " + after):
foundKeyword = True
normalized_text = content[sent["beginOffset"]:mentionBegin] + " _entity_ " + content[mentionEnd:sent["endOffset"]]
if (label and foundKeyword) or (label == False):
sentences[normalized_text] = {"label":label, "validation":validation, "diffbotUri":entity["diffbotUri"], "name" : ground_truth[entity["diffbotUri"]]["name"]}
Randomly sampling 80% of the ground_truth.tsv list for training ensures that we’re not accidentally biasing the classifier. The remaining 20% will be used to evaluate the classifier with data it has not seen (important to ensure the classifier is learning general patterns about sanction statements rather than patterns only found in the training data).
Note that we also replaced the organization name in each sentence with a generic _entity_ label. There are two reasons for doing this.
- Given a sentence with more than one organization mentioned, it is possible for one organization to be announcing sanctions but not the other. Labeling the entity to be considered allows the classifier to better understand context. (i.e. “Corporate Travel Management has suspended its partnerships with Moscow-based agency Unifest…”)
- The actual name of an organization is irrelevant to predicting sanctions. Scrubbing it ensures the classifier doesn’t attempt to use name as a variable for prediction.
Next, we’ll divide the sentences into two files. A training list (80%) and a validation list (20%). As mentioned, the former will be used by fasttext to train the classifier. The second will be used to assess its performance.
train = open("training.txt", "w")
val = open("validation.txt", "w")
for (sentence, obj) in sentences.items():
label = "__label__"+str(obj["label"])
line = label + " " + sentence
if obj['validation']:
val.write(line + "\n")
else:
train.write(line + "\n")
train.close()
val.close()
Save these 3 scripts into a single file called 3_prepare_training.py.
This is a sample of what training.txt and validation.txt looks like.
__label__True PARIS — French car giant Renault says _entity_ will immediately suspend operations at its Moscow factory after Kyiv called for a boycott of the company for remaining in Russia.
__label__False Renault is also considering “the possible options” for its Russian affiliate _entity_ , the company says in a statement, adding that it had downgraded its 2022 financial outlook.
We’re now ready to train the classifier. With our data all setup, this is actually quite simple.
import fasttext
# train classifier
model = fasttext.train_supervised(input="training.txt", lr=0.1, epoch=25, wordNgrams=2)
model.save_model("model.bin")
# load and evaluate classifier
model = fasttext.load_model("model.bin")
print("evaluation:")
print("number of samples, precision and recall: " + str(model.test("validation.txt")))
print("examples:")
example1 = "France’s Renault, which controls Russian car maker _entity_ , fell 9.3 per cent."
print(str(model.predict(example1)) + " for: " + example1)
example2 = "Germany's Lufthansa halted flights to Ukraine from Monday, joining _entity_ which already suspended flights."
print(str(model.predict(example2)) + " for: " + example2)
Save this as 4_train_model.py.
Fasttext will spit out two figures — precision and recall. Shruti Saxena does an amazing job explaining the difference between the two, but suffice to say, we want high numbers for both.
Seeding our established ground_truth.tsv file, we were able to get a precision of 0.94 and a recall of 0.94 over 6804 sentences.
If you’re not happy with the classifier’s results, simply add more organizations to ground_truth.tsv and re-run the training.
Step 4 — Use the Classifier to Predict Sanctions
We’re finally here! All that work training your custom classifier is finally paying off. Practically speaking, all we need to do is load the fasttext model
import fasttext
model = fasttext.load_model("model.bin")
Then use the model against a sentence
prediction = model.predict(sentence_for_classification)
And loop this through every sentence in facts.jsonl.
Everything else is data gravy. We chose to also enhance the output with additional firmographic details like industries, logos, and summaries for each company, then package all of it up into a single json and TSV file for easy human review. See 5_generate.py in the repo for the full details on how we did this.
At the end of each human review, feed both positives and negatives into your ground_truth.tsv list to help seed the next build of your classifier.
For context, we ran about 2-3 rounds of human review over the course of building this tracker before feeling confident in its precision/recall figures.
What’s Next?
I’m not a data scientist. Far from it in fact. But in the span of a single tutorial, I’ve built a market monitoring system generating insights in minutes that otherwise would’ve taken months of collective manual research.
Tracking sanctions is only the tip of the iceberg. The same system can be extended to track all kinds of signals in real-time.
- Government tenders
- Supply chain partnerships
- SEC filings
- Privacy policies
The technology to structure signal out of the noisy web is available today, and I’m excited to share more intelligent systems in upcoming posts. Stay in touch on Twitter or LinkedIn.
Jerome Choo
Growth at Diffbot