Extract Content From
Websites Automatically
Scrape articles, product pages, discussions, and more without any rules.
Try Extracting a Web PageReady to jump right in? Get started for free.
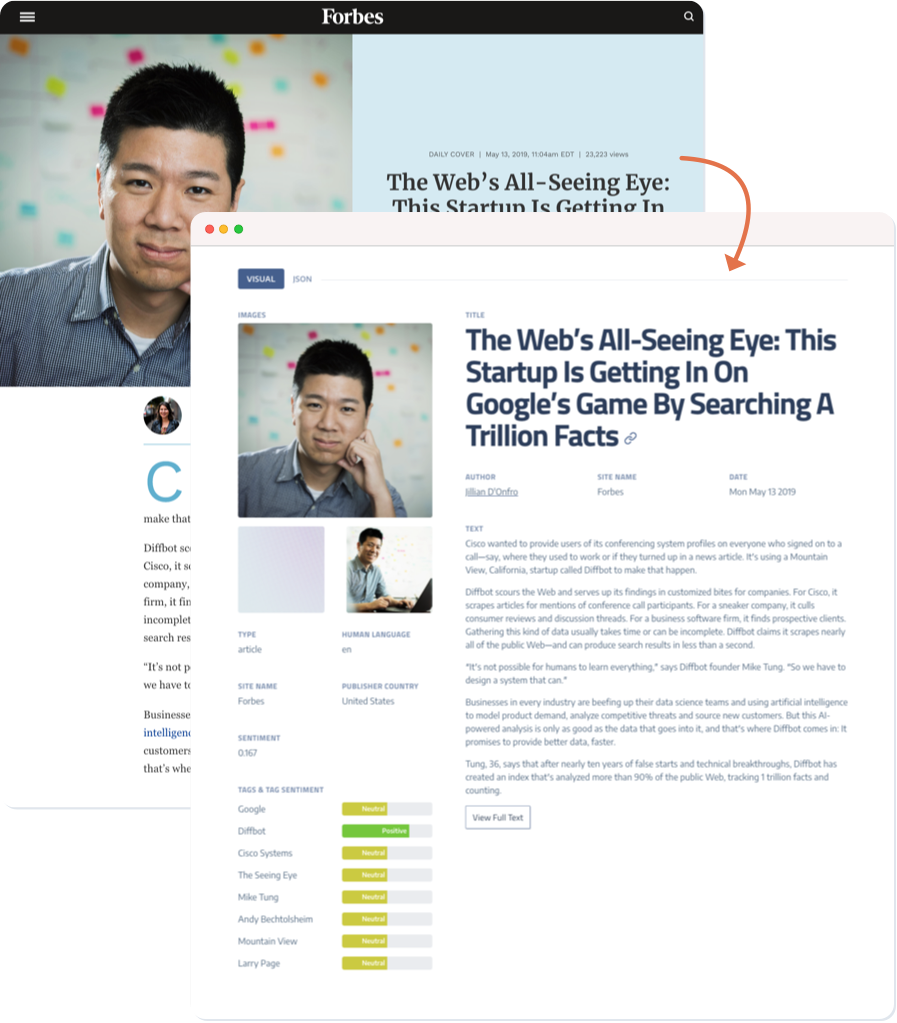
Reads Websites like Humans
As a human, you're probably pretty good at telling a product page from a news article, or getting an idea of what a title says about the website you're reading.
What if you need to do that 10,000 times a minute? You could hire a lot more humans, or you could let Diffbot read it for you.
How it Works
Unlike traditional web scraping tools, Diffbot doesn't require any rules to read the content on a page.
It starts with computer vision, which classifies a page into one of 20 possible types. Content is then interpreted by a machine learning model trained to identify the key attributes on a page based on its type.
The result is a website transformed into clean structured data (like JSON or CSV), ready for your application.
# Python + Diffbot Extract
import requests
url = 'https://api.diffbot.com/v3/analyze?token=TOKEN&url=URL'
response = requests.request('GET', url)
print(response.text)
Effortless API Access
Our REST API schema is so simple and familiar, this is all you need to get started 👉.
Need to tweak more advanced settings? We've got those too.
Speaks Any Language
Thanks to its basis in computer vision, Diffbot Extract works with any human language.

Crawl + Extract = 🚀
Pair Extract with Crawl to automatically generate a database of all the products on a website, or all the articles of a news site.