Crawl Every Page of
Any Website
Turn any site into a structured database of all their products, articles, and discussions in minutes. Extract at the scale of the web.
Schedule a DemoReady to jump right in? Get started for free.

No Rules Necessary
Like Extract, Crawl requires no rules. Simply point Crawl to a starting point on a website and it'll spider through every link on that page and extract them all.
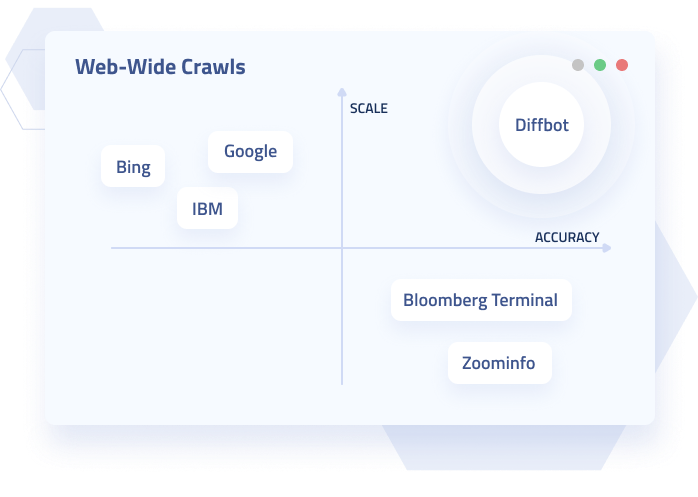
Insanely Fast
Diffbot's distributed, world-class crawling infrastructure processes millions of pages daily.
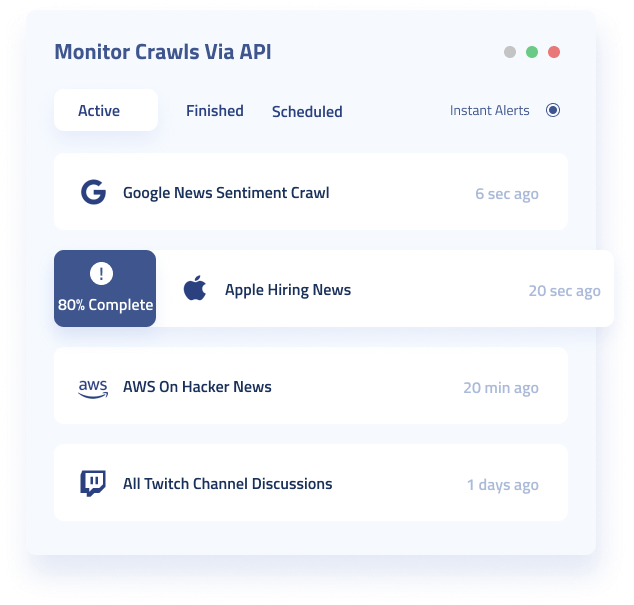
Complete API Accessibility
Programmatically start crawls, check crawl statuses, and retrieve output using the Crawl API.
See How Crawl Works
Crawlbot Basics
In this introductory Crawlbot video we work through how to set up a basic crawl to extract product data from across an ecommerce site.
Extracting Pages with Crawlbot
In this video we look at how Crawlbot works with Extract, and how to choose the best extraction API to process pages found by Crawlbot.
Advanced Crawlbot Techniques
In this video we look at some of the more advanced techniques available using Crawlbot, including crawling pages that are behind logins.