Crawlbot
Crawlbot allows you to apply a Diffbot API to entire sites, returning the complete structured data in JSON or CSV format.
Overview
Crawlbot works hand-in-hand with a Diffbot API (either automatic or custom). It quickly spiders a site for appropriate links and hands these links to a Diffbot API for processing. All structured page results are then compiled into a single "collection," which can be downloaded in full or searched using the Search API.
Note that the limit of active crawls on a single token is 1000. More information here.
Creating a Crawl: Basics
Each crawl requires, at minimum, the following:
- A crawl name (e.g., "DiffbotCrawl").
- A starting or "seed" URL. Multiple URLs can be provided to process more than one site in the same crawl. If the seed contains a non-www subdomain ("http://blog.diffbot.com" or "http://support.diffbot.com") Crawlbot will restrict spidering to the specified subdomain. If you wish to expand your crawl to multiple domains, enter each one as a separate seed; or consider the
restrictDomainsetting. Read more. - A Diffbot API to be used for processing pages.
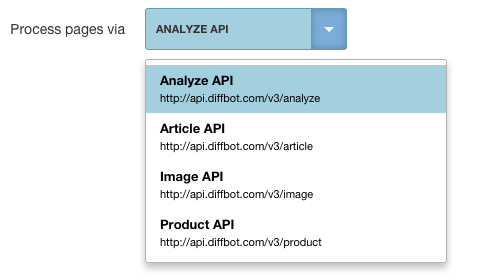
Creating an Automatic Crawl Using the Analyze API
The simplest Crawlbot crawl will apply Diffbot's Analyze API to a single site. The Analyze API determines the "page-type" of submitted URLs, and automatically extracts the contents if the page-type is currently supported.
To run your crawl:
- Enter a new crawl name.
- Enter a seed URL, like "http://blog.diffbot.com."
- Select the Analyze API from the "Diffbot API" menu.
- Click "Start"
In this situation, each page found on the site will be analyzed -- and all supported page-types (article, discussion, image, product, etc.) will be automatically extracted and made available in the resulting collection.
Creating a Crawl Using a Specific Extraction API
If you don't want to rely on the Analyze API's analysis of pages, you can use a specific Diffbot extraction API (e.g., Product or Article API). Because by default all pages on a domain will be processed by the API you select, in nearly all of these circumstances you will want to further narrow your crawl using the Crawl or Processing Patterns (or regular expressions), discussed below.
Controlling or Limiting Pages to Crawl
By default, Crawlbot will spider and process all links on the domain(s) matching your seed URL(s). You can limit which pages of a site to crawl (spider for links), and which pages of a site to process, using the "Crawling Limits" and "Page Processing Limits" sections.
Crawl Patterns
Crawl patterns will limit crawling to only those URLs containing at least one of the matching strings. You may enter as many crawl patterns as you like, one per line. Any URLs not containing a match will be ignored.
For example, to limit crawling at diffbot.com to only "blog.diffbot.com" pages, you can enter a crawl pattern of blog.diffbot.com. If you only wanted to crawl the "Shoes" section of a site, you might enter a crawl pattern of /category/shoes.
You can also supply negative crawl patterns by prepending your pattern with a "!" (exclamation point). You can supply as many negative patterns as you like. All matching URLs will be skipped.

You can also use the ^ and $ characters -- borrowed from regular-expression syntax -- to specify the start and end of a pattern. For instance, ^http://www.diffbot.com will match URLs starting with "http://www.diffbot.com," and type=product$ will match all URLs ending in "type=product."
Page Processing Patterns
Page processing patterns are identical to crawling patterns, except they define which pages will be processed by the selected Diffbot API.
For example, to only process product pages for a site you might enter a page processing pattern of "/product/detail/" -- this would match a URL like http://shopping.diffbot.com/product/detail/8117a7?name=diffy_robot, but would not match the URLs http://shopping.diffbot.com or http://shopping.diffbot.com/category/plush.

Crawl and Page Processing Regular Expressions
If you know your way around regular expressions, you can write a crawl or page processing regex in place of patterns.
If you supply a regex, any patterns will be ignored: only the URLs that contain a match to your provided expression will be crawled and/or processed.
HTML Processing Patterns
The HTML Processing Pattern allows you to require exact markup strings that must be found in the page HTML in order for a page to be processed. For example, if a site's articles all contain the string:
<div class="articleBody"></div>You can specify an HTML Processing Pattern of class="articleBody" to limit processing only to the article pages (those containing the string in their HTML).
Pages to Process / Pages to Crawl
You can also set a fixed number of pages to crawl or process. Your crawl will complete as soon as one of these is reached.
By default, crawls are set to process and crawl a maximum of 100,000 pages.
Passing Diffbot API Querystring Arguments
Crawlbot hands off URLs to specific Diffbot APIs for processing. Each of these APIs has optional querystring arguments that can be used to modify the information returned -- most commonly the fields argument, for adding optional fields to the Diffbot response.
Robots.txt and Politeness
By default Crawlbot adheres to robots.txt instructions, including the crawlDelay parameter. In rare cases -- e.g., when crawling a partner's site with permission -- Crawlbot can be configured to ignore robots.txt instructions.
Crawlbot also has a default "politeness" setting of 0.25 seconds -- spidering machines will wait a quarter of a second between page-loads in order to minimize the impact of sites being crawled. You can adjust this on a per-crawl basis.
Repeating Crawls
You can optionally set crawl jobs to repeat automatically. Each repeat crawl "round" will fully re-spider from each seed URL, and process pages according to your repeat settings.
For each URL:
- If the URL was previously processed, and the extracted data is different (e.g., a price change), the data will be updated and the
timestampvalue in the JSON response will be updated to indicate an updated record. - If the URL was previously processed and the extracted data is the same as the previous round (no changes), the data will remain the same and the
timestampvalue in the JSON response will not be updated. - If the URL is brand new, it will be processed for the first time.
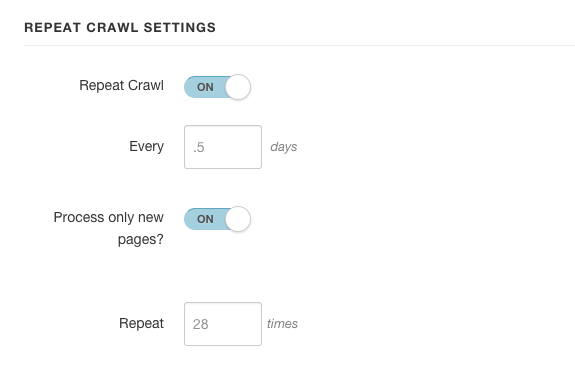
You can optionally choose to "only process if new," which will only process newly-discovered URLs. In this case, pages of a site will only be processed once -- regardless of the number of rounds. If "only process if new" is not selected, all pages in the site (and matching the process pattern / regular expression) will be processed each round.
You will also need to indicate:
- Repeat frequency: this is indicated in days ("1" for daily; "7" for weekly; "0.25" for every six hours).
- Number of repeats. Set to 0 or leave blank to repeat indefinitely.
Repeat timing is based on the end of the previous crawl round. So if a daily ("1") repeating crawl ends on Tuesday at 12:00pm, the next round will start on Wednesday at noon. Using the Crawlbot API you can use the roundStart argument to control when your repeating crawl rounds start.
Notifications
You can choose to be notified at the conclusion of each crawl (or crawl round, if your crawl is repeating), either by webhook or email.
If "webhook" is chosen, you will need to supply a URL that is capable of receiving a POST request. One alternative to building your own: use the Diffbot app on Zapier to receive webhook notifications.
Accessing Crawl Data
You can access processed data anytime during a crawl, or after it completes. Crawlbot offers two download options within the interface:
- Full JSON Output: A single file, in valid JSON, containing all of the processed objects from your crawl.
- CSV Output: A single comma-separated-values file of the top-level objects. Nested elements (article images, tags, etc.) will not be returned in the CSV.
If you only want to access a subset of your data, the Search API allows much more flexibility in searching and retrieving only the matching items from queries.
The URL Report
Also provided with each crawl is a downloadable (CSV) report on each page crawled and/or processed within a crawling job. This file is a log of each URL analyzed by Crawlbot, and is useful in diagnosing issues -- "Why wasn't this page processed?" -- or simply cataloguing which URLs have been processed.
Each row in the URLs report contains diagnostic information, including:
- Whether the URL was processed by a Diffbot extraction API
- Crawling timestamp
- Last status of the URL