
Our Values
We believe that democratizing access to a common knowledge base of facts will lead to more intelligent and trustworthy systems. We embrace growth, empowerment, empathy, original thinking, and aren't afraid to tackle big challenges.
State-of-the-Art Research
Our applied research team consists of the foremost experts in areas such as: structured document extraction, entity linking, relation extraction, coreference resolution, knowledge inference, knowledge fusion, and information retrieval.
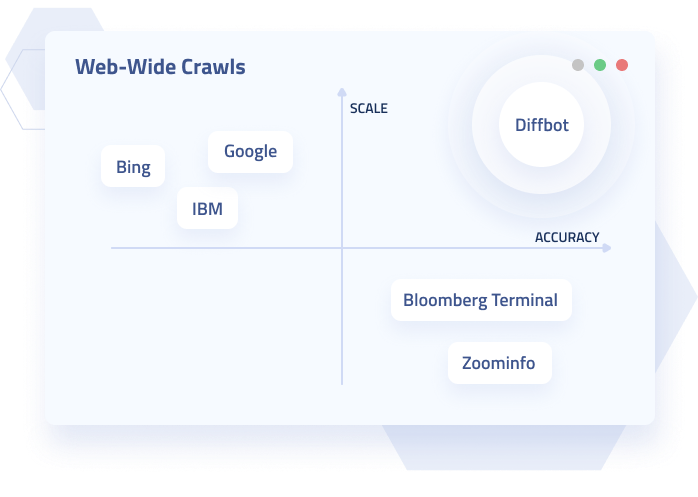
Web-Scale Engineering
Diffbot runs its own crawl of the entire public web, independent from Google and Bing, on our own custom-assembled hardware, out of our own datacenter in California. We're one of the few places you can work on web-scale machine learning, distributed systems, and search engines in a fast-moving startup environment.
Diffbot In The News

This know-it-all AI learns by reading the entire web nonstop
Sept 4, 2020
Diffbot is building the biggest-ever knowledge graph by applying image recognition and natural-language processing to billions of web pages...
AI bringing truth to data journalism
Sept 10, 2019
Wouldn't it be fabulous to know for sure that an article you read online is authentic and contains trusted sources? If everyone used AI to fact check, fake news and data could be eliminated permanently from online news sites...

This startup is Getting In On Google's Game By Searching A Trillion Facts
May 13, 2019
Cisco wanted to provide users of its conferencing system profiles on everyone who signed on to a call—say, where they used to work or if they turned up in a news article. It’s using a Mountain View, California, startup called Diffbot to make that happen...
Contact Us
333 Ravenswood Ave, Menlo Park, CA 94025
General Inquiries
For all other general inquiries related to Diffbot
Mike Tung, CEO
mike@diffbot.com